
APMCM23-C
摘要
- In the first problem, patent numbers, subsidies, per capita disposable income, and charging station quantities from 2010 to 2022 are collected and used as influencing factors.
专利数量、政策补贴、人均可支配收入多因素分析基本要素。
- The sales volume of new energy vehicles is the dependent variable.
- The order of importance is determined as subsidies, patents, per capita income, and charging station growth rate. 摘要处直接陈述因素重要性排序。
模型假设
- Assuming that the data obtained from the search has a certain degree of credibility and rationality. 自己找数据题必备假设
问题一
Data Source
列表写出数据来源
In order to analyze the main factors that affect the development of new energy electric vehicles in China, relevant data sets need to be collected. Owing to various statistical departments associated with distinct elements, the Table 1 below illustrates the origins of the data sets utilized in this chapter alongside the explanations of variables.
- Ministry of Industry and Information Technology of China
- Autopat website 查相关专利申请
- National Bureau of Statistics 查人均可支配
- China Electric Vehicle Charging Infrastructure Promotion Alliance
最大最小归一:
In order to eliminate the influence of different dimensions of each set of data and facilitate the construction of a multivariate regression model, data for each variable should be normalized. Due to the relatively stable nature of the data without extreme outliers in its maximum and minimum values, this paper utilizes min-max normalization to process the data. It can be represented by the following formula
模型
论述中位数人均收入的优越性:
It should be noted that the personal disposable income here is the median, not the average. For the median represents the middle value when all incomes are arranged in ascending order, offering a more robust measure that is not as heavily influenced by the extreme values.
Result
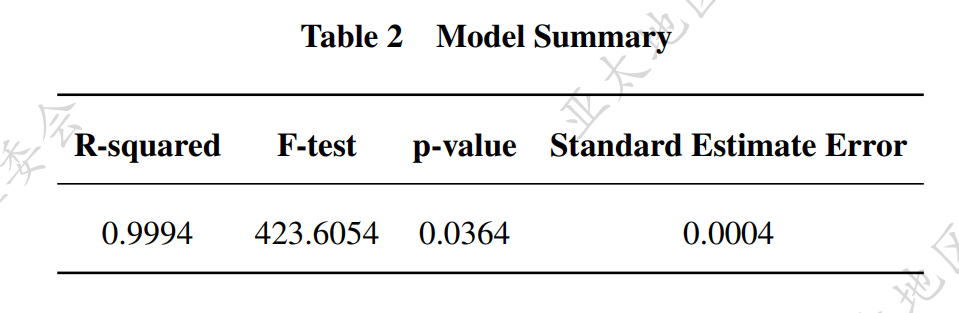
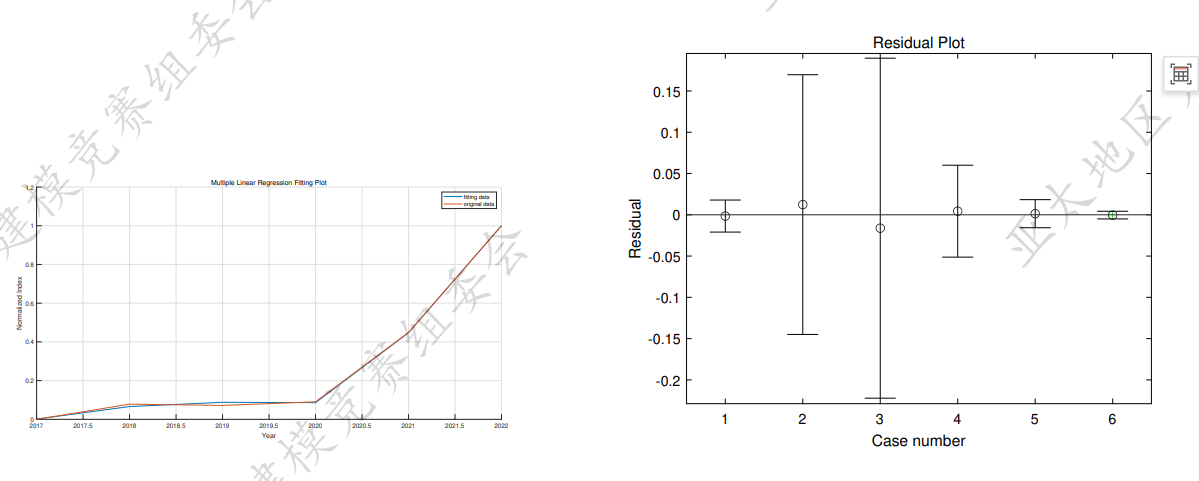
问题二
Data
来源和处理:取对数
Since it is observed that the initial data has exponential growth properties (refer to the left pictures in Figures 2 and 3), we perform logarithmic processing on the original data. The data after logarithmic processing is more stable and can make the time series more stable (refer to the pictures on the right of Figures 2 and 3). These data are now prepared and ready to be used for model fitting.
ARIMA
详细步骤和叙述参考原文
问题三
对传统汽车的影响:
Optimal Species Competition Model in Math Modeling
问题四
逐条列出Policy
Difference-in-Differences Model(政策影响就用它!)
A difference-in-difference (DID) model is a statistical method used to estimate the causal effects of policy interventions by comparing changes in outcomes over time between experimental and control groups. The model is based on the traditional difference-in-difference (DID) approach, incorporating multiple time periods and/or multiple groups. The time series settings of policy nodes in our DID model are as follows: when there is a policy, the sequence value takes 1, and when there is no policy, it takes 0. Use the DID model to test the causal relationship between export volume and whether the policy is enacted, and give the correlation (negative correlation) Judging from the existing monthly export volume data (October 2021 to October2023), China’s export volume of new energy electric vehicles is gradually rising. There- fore, we set the control group data that is not affected by the policy to be the arithmetic sequence distribution from the first group to the last group of existing data, and conduct DID model testing.
